Transformers: como funciona o mecanismo de atenção

Quando comecei a me interessar por LLM's, me deparei com um conceito que até então era novo pra mim: o mecanismo de atenção em transformers. No começo era extremamente abstrato, mas depois de certa dedicação aos estudos tudo começou a fazer sentido.
Meu objetivo nesse post é te guiar em uma linha de raciocínio simplificada para entender como funciona o mecanismo de atenção em um transformer e como ele é capaz de modificar um embedding para enriquecer com informações contextuais.
Definição dos Embeddings
No mundo do processamento de linguagem natural (PNL), cada palavra de um vocabulário pode ser representada por um vetor numérico, conhecido como "embedding". Esses embeddings são fundamentais porque capturam não apenas o significado semântico das palavras, mas também informações sintáticas e relações contextuais.
No nosso caso, vamos adotar um embedding extremamente simplificado, atribuindo manualmente embeddings tridimensionais a cinco palavras diferentes. Cada ponto nesse espaço tridimensional reflete características únicas da palavra, permitindo que o modelo diferencie e reconheça padrões nas relações entre palavras.
Vamos começar definindo os embeddings para transformar um texto em um vetor numérico. Adotando um processo extremamente simples, vamos criar um embedding com 3 dimensões pautadas nos seguintes critérios:
- Primeira dimensão: Entretenimento. Reflete quão relacionada a palavra é com conceitos de entretenimento ou cultura.
- Segunda dimensão: Temporalidade. Indica a relação da palavra com conceitos de tempo ou duração.
- Terceira dimensão: Importância. Representa a importância ou o peso semântico da palavra no discurso.
Com essa lógica, um embedding para as palavras do texto "o filme começa em breve" poderia ser:
import torch
vocab_embeddings = {
# Valor baixo em 'importância'
"o": torch.tensor([1.0, 1.0, 1.0]),
# Alto em 'entretenimento', baixo em 'importância'
"filme": torch.tensor([4.0, 2.0, 1.0]),
# Alto em 'temporalidade', baixo em 'entretenimento'
"começa": torch.tensor([1.0, 4.0, 3.0]),
# Moderado em 'temporalidade', baixo em 'importância'
"em": torch.tensor([1.0, 1.0, 1.0]),
# Muito alto em 'temporalidade', baixo em 'entretenimento'
"breve": torch.tensor([1.0, 5.0, 4.0]),
}
Em seguida, vamos criar uma matriz de embeddings com essas 5 palavras.
embedding_matrix = torch.stack(list(vocab_embeddings.values()))
print(embedding_matrix)tensor([[1., 1., 1.], [4., 2., 1.], [1., 4., 3.], [1., 1., 1.], [1., 5., 4.]])
Cálculo dos Scores de Atenção
Os scores de atenção são calculados tomando o produto escalar entre os embeddings de todas as palavras, medindo assim a relevância ou a "atenção" que cada par de palavras deve um ao outro. Este cálculo destaca a similaridade entre as palavras: quanto maior o score, maior a relevância percebida. No mecanismo de atenção, isso é usado para determinar quão fortemente cada palavra deverá influenciar as outras na representação final. É como se cada palavra "votasse" na importância das outras palavras com base em sua relação mútua.
No nosso caso, podemos calcular os scores de atenção como:
scores = torch.mm(embedding_matrix, embedding_matrix.t())
print("Scores de Atenção:\n", scores.numpy())Scores de Atenção: [[ 3. 7. 8. 3. 10.] [ 7. 21. 15. 7. 18.] [ 8. 15. 26. 8. 33.] [ 3. 7. 8. 3. 10.] [10. 18. 33. 10. 42.]]
Segundo essa matriz, o score de atenção entre "começa" (posição 2 - linha 2) e "breve" (posição 4 - coluna 4), por exemplo, é 33. Para clarificar a origem desse valor, vamos reproduzir essa conta manualmente para essas duas palavras. Os embeddings para "começa" são [1.0, 4.0, 3.0] e para "breve" são [1.0, 5.0, 4.0].
- Primeiro, multiplicamos cada elemento do embedding de "começa" pelo correspondente no embedding de "breve":
- 1.0 × 1.0 = 1.0
- 4.0 × 5.0 = 20.0
- 3.0 × 4.0 = 12.0
- Somamos os resultados das multiplicações elemento a elemento para obter o score de atenção total:
- 1.0 + 20.0 + 12.0 = 33.0
Portanto, o score de atenção entre "começa" e "breve" é 33.0, conforme também observado na matriz de scores de atenção impressa. Este valor reflete a similaridade e a relevância entre as representações dessas duas palavras, indicando uma forte relação ou influência mútua no contexto desse conjunto específico de embeddings.
Normalização dos Scores
Após o cálculo dos scores brutos de atenção, aplicamos a função softmax para normalizá-los em uma distribuição de probabilidade. Esta etapa é crucial, pois transforma os scores em pesos que somam 1, permitindo que sejam interpretados como a probabilidade de cada palavra ser relevante no contexto dado. O softmax garante que palavras com scores mais altos tenham pesos proporcionalmente maiores, enfatizando as relações mais significativas e diminuindo a influência das menos relevantes.
Aplicando a função softmax na matriz de scores, obteremos uma matriz cujo somatório de cada linha é 1.
weights = softmax(scores, dim=-1)
print("Pesos de Atenção:\n", weights.numpy())Pesos de Atenção: [[7.6825888e-04 4.1945513e-02 1.1401973e-01 7.6825888e-04 8.4249818e-01] [7.9022567e-07 9.5032877e-01 2.3556296e-03 7.9022567e-07 4.7314081e-02] [1.3875290e-11 1.5216102e-08 9.1105112e-04 1.3875290e-11 9.9908888e-01] [7.6825888e-04 4.1945513e-02 1.1401973e-01 7.6825888e-04 8.4249818e-01] [1.2662603e-14 3.7746684e-11 1.2339458e-04 1.2662603e-14 9.9987662e-01]]
Para entender o passo a passo desse cálculo, vamos calcular o resultado de softmax da palavra "o" cujo vetor de scores é [3, 7, 8, 3, 10].
- Cálculo da Exponencial de Cada Score:
Para cada score na lista, calculamos a exponencial (e^score), porque a função softmax transforma os scores usando a função exponencial para garantir que todos os valores sejam positivos e para amplificar as diferenças entre os scores.- Scores:
[3, 7, 8, 3, 10] - Exponenciais:
[e^3, e^7, e^8, e^3, e^10]
- Scores:
- Soma das Exponenciais:
Somamos todas as exponenciais dos scores para obter o denominador do softmax.- Soma:
e^3 + e^7 + e^8 + e^3 + e^10
- Soma:
- Divisão para Obter as Probabilidades:
Dividimos a exponencial de cada score pela soma total das exponenciais para obter a probabilidade normalizada para cada palavra. A probabilidade para "em" -> "começa", por exemplo, é 0.114 (linha 0, coluna 2).
Cálculo dos Outputs da Atenção
Com os pesos de atenção normalizados em mãos, calculamos o output da atenção para cada palavra. Isso é feito criando uma soma ponderada dos embeddings originais, onde os pesos determinam a contribuição de cada embedding para o resultado final. Essencialmente, isso permite que o modelo crie uma representação enriquecida que destaca as informações mais importantes de acordo com o contexto das palavras envolvidas. O resultado é um conjunto de embeddings que são adaptados dinamicamente para refletir as nuances do texto analisado.
Calculando os outputs da atenção como soma ponderada dos embeddings, temos:
attn_outputs = torch.mm(weights, embedding_matrix)
print("Outputs da Atenção:\n", attn_outputs.numpy())Outputs da Atenção: [[1.1258365 4.7539973 3.755534 ] [3.8509862 2.1466522 1.1466535] [1. 4.999089 3.9990888] [1.1258365 4.7539973 3.755534 ] [1. 4.9998765 3.9998767]]
Para resolver um exemplo manualmente para a palavra "filme", precisamos primeiro observar os pesos normalizados de atenção para essa palavra. No nosso caso, o vetor para a palavra "filme" está na linha 3 da matriz de pesos normalizados [7.9022567e-07 9.5032877e-01 2.3556296e-03 7.9022567e-07 4.7314081e-02] .
Isso significa que os pesos de atenção normalizados são:
- Para "o":
7.9022567e-07 - Para "filme":
9.5032877e-01 - Para "começa":
2.3556296e-03 - Para "em":
7.9022567e-07 - Para "breve":
4.7314081e-02
Embeddings das palavras:
- "o":
[1.0, 1.0, 1.0] - "filme":
[4.0, 2.0, 1.0] - "começa":
[1.0, 4.0, 3.0] - "em":
[1.0, 1.0, 1.0] - "breve":
[1.0, 5.0, 4.0]
Cálculo do Output da Atenção para "filme"
Para calcular o output da atenção para "filme", multiplicamos cada embedding pelo peso de atenção correspondente e somamos os resultados. A operação para cada dimensão do embedding resultante será:
Primeira dimensão:
(7.9022567e−7×1.0)+(9.5032877e−1×4.0)+(2.3556296e−3×1.0)+(7.9022567e−7×1.0)+(4.7314081e−2×1.0)=3.80131508+0.0023556296+0.047314081=3.850985(7.9022567e−7×1.0)+(9.5032877e−1×4.0)+(2.3556296e−3×1.0)+(7.9022567e−7×1.0)+(4.7314081e−2×1.0)=3.80131508+0.0023556296+0.047314081=3.850985
Segunda dimensão:
(7.9022567e−7×1.0)+(9.5032877e−1×2.0)+(2.3556296e−3×4.0)+(7.9022567e−7×1.0)+(4.7314081e−2×5.0)=1.90065754+0.0094225184+0.236570405=2.146650463(7.9022567e−7×1.0)+(9.5032877e−1×2.0)+(2.3556296e−3×4.0)+(7.9022567e−7×1.0)+(4.7314081e−2×5.0)=1.90065754+0.0094225184+0.236570405=2.146650463
Terceira dimensão:
(7.9022567e−7×1.0)+(9.5032877e−1×1.0)+(2.3556296e−3×3.0)+(7.9022567e−7×1.0)+(4.7314081e−2×4.0)=0.95032877+0.0070668888+0.189256324=0.946651983(7.9022567e−7×1.0)+(9.5032877e−1×1.0)+(2.3556296e−3×3.0)+(7.9022567e−7×1.0)+(4.7314081e−2×4.0)=0.95032877+0.0070668888+0.189256324=1.1466535Com esses pesos de atenção, o embedding resultante para "filme", após aplicar a atenção, seria aproximadamente [3.8509862 2.1466522 1.1466535] e não mais o embedding original [4.0, 2.0, 1.0].
Embedding Pós-Atenção
Para entender essa transformação, precisamos observar os pesos de atenção que foram atribuídos, especialmente o alto peso (aproximadamente 95.032877%) conferido ao próprio "filme". Essa porcentagem não é apenas um número; ela é um indicador potente de quão central é a ideia de "filme" dentro do conjunto de palavras considerado. Em outras palavras, o mecanismo de atenção reconheceu que, dentro desse contexto específico, "filme" merece a maior parte da atenção.
Isso demonstra como os pesos de atenção direcionam a composição do embedding final, destacando a auto-relevância de "filme" e moderando a influência das outras palavras com base nas relações contextuais capturadas pelos pesos de atenção.
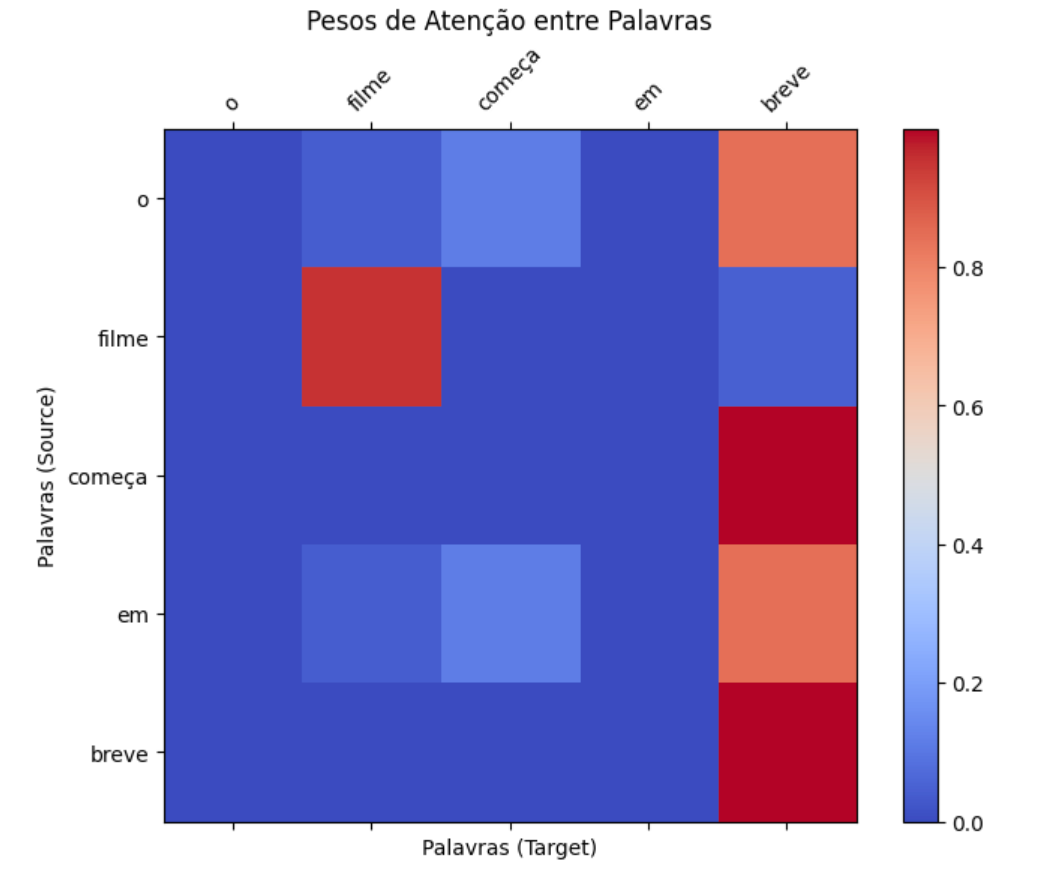
De outro lado, analisando o embedding da palavra "em", vemos que o alto peso dado a "breve" sugere uma conexão temporal forte, enfatizando o contexto iminente ou a proximidade dos eventos descritos. Assim, "em" não é apenas uma palavra funcional; através da atenção, ela se torna um veículo que carrega consigo um significado extraído de seu ambiente imediato "em breve". Isso se torna óbvio ao observar o embedding de "em" antes [1.0, 1.0, 1.0] e o embedding de "em" depois [1.1258365 4.7539973 3.755534 ], mudança fortemente influenciada pelo embedding original de "breve" [1., 5., 4.].
Uma forma mais visual de observar esse efeito é através da matriz de pesos de atenção entre as palavras. Note que o peso da atenção entre "em" e "breve" é relativamente alto, o que significa que existe uma relação entre essas palavras naquele contexto. Da mesma forma, existe uma relação ainda mais forte entre "começa" e "breve".
Generalizando o Transformer
Até aqui, adotei um processo extremamente manual para exemplificar o processo e o funcionando do transformer, isso incluiu definir um embedding manualmente. Entretanto, é possível utilizar modelos já treinados para realizar o processo de embedding.
No exemplo abaixo eu aproveito o tokenizador de um modelo BERT pré-treinado para gerar os embeddings. O resultado é o equivalente ao embedding de 3 dimensões que usei no exemplo anterior. A diferença, claro, é que o embedding resultante é extremamente mais complexo e completo, possuindo uma quantidade muito maior de dimensões. Além disso, esse embedding considera tokens e não palavras.
import torch
from math import sqrt
import torch.nn.functional as F
from torch import nn
from transformers import AutoConfig
from transformers import AutoTokenizer
from bertviz.transformers_neuron_view import BertModel
from bertviz.neuron_view import show
model_ckpt = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = BertModel.from_pretrained(model_ckpt)
text = "O filme começa em breve"
config = AutoConfig.from_pretrained(model_ckpt)
token_emb = nn.Embedding(config.vocab_size, config.hidden_size)
inputs = tokenizer(text, return_tensors='pt', add_special_tokens=False)
inputs_embeds = token_emb(inputs['input_ids'])
print(inputs_embeds.size())
print(inputs_embeds)
torch.Size([1, 8, 768]) tensor([[[-4.1795e-01, 1.2192e-04, 4.1634e-01, ..., 5.4545e-01, 5.0514e-01, -6.0699e-01], [ 2.5456e-01, 3.0156e-01, 1.7096e+00, ..., 7.1533e-01, -2.9525e-01, 2.7176e+00], [ 1.2736e+00, 1.4583e+00, 3.0885e-01, ..., -1.8284e+00, -9.1102e-01, -1.8708e-01], ..., [ 6.7892e-01, 2.3083e+00, -2.8318e-01, ..., -1.9142e+00, -2.2213e-01, -6.0820e-01], [ 1.7550e-01, -2.6884e-01, 9.8706e-01, ..., 3.4548e-01, 3.3960e-02, 2.1218e+00], [ 5.7823e-01, 3.5524e-02, 2.8755e+00, ..., -3.3926e-01, -8.6781e-01, 1.2969e+00]]], grad_fn=<EmbeddingBackward0>) [ ]:
Em posse do embedding do texto, podemos repetir todo o processo realizado anteriormente: gerar os scores de atenção, normalizar com softmax e, em seguida, gerar o novo embedding após a atenção.
query = v_key = value = inputs_embeds
dim_k = v_key.size(-1)
scores = torch.bmm(query, v_key.transpose(1, 2))/sqrt(dim_k)
weights = F.softmax(scores, dim=-1)
attn_outputs = torch.bmm(weights, value)
print(attn_outputs)tensor([[[ 0.9947, -0.4364, -0.3107, ..., -0.1831, -0.5908, 0.5918], [-0.9229, -1.9675, 0.2907, ..., 0.5829, 0.3023, 1.1418], [-1.5374, 0.1489, 0.9614, ..., 1.2112, -1.7464, 0.8496], ..., [ 0.4573, -0.6305, 1.0832, ..., -1.5323, 0.7004, -0.1562], [ 0.1049, 0.9949, -0.2433, ..., 0.1060, 0.6420, 0.4694], [-0.0202, 1.1358, -1.2976, ..., -1.3733, 1.5542, -1.2044]]], grad_fn=<BmmBackward0>)
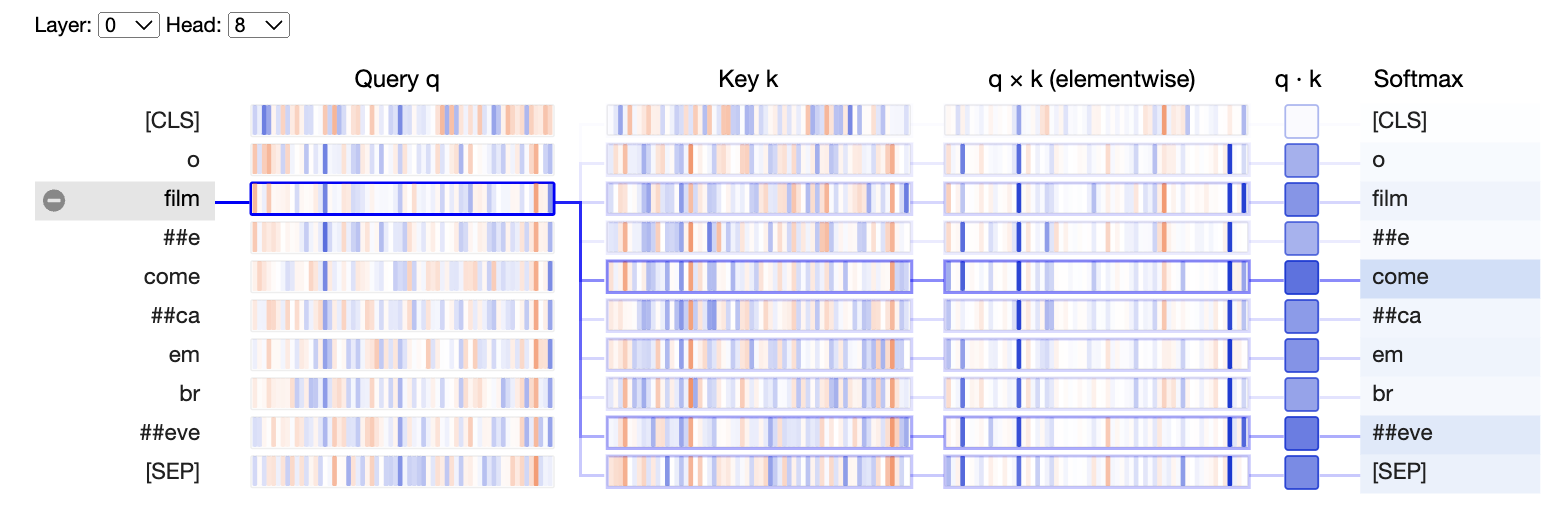
Podemos visualizar o resultado de todo esse processo de atenção e notar que o token "film" ("equivalente" a palavra "filme") possui um alto grau de atenção com o token "come" ("equivalente" a palavra "começar").
show(model, "bert", tokenizer, text, display_mode="light", layer=0, head=8)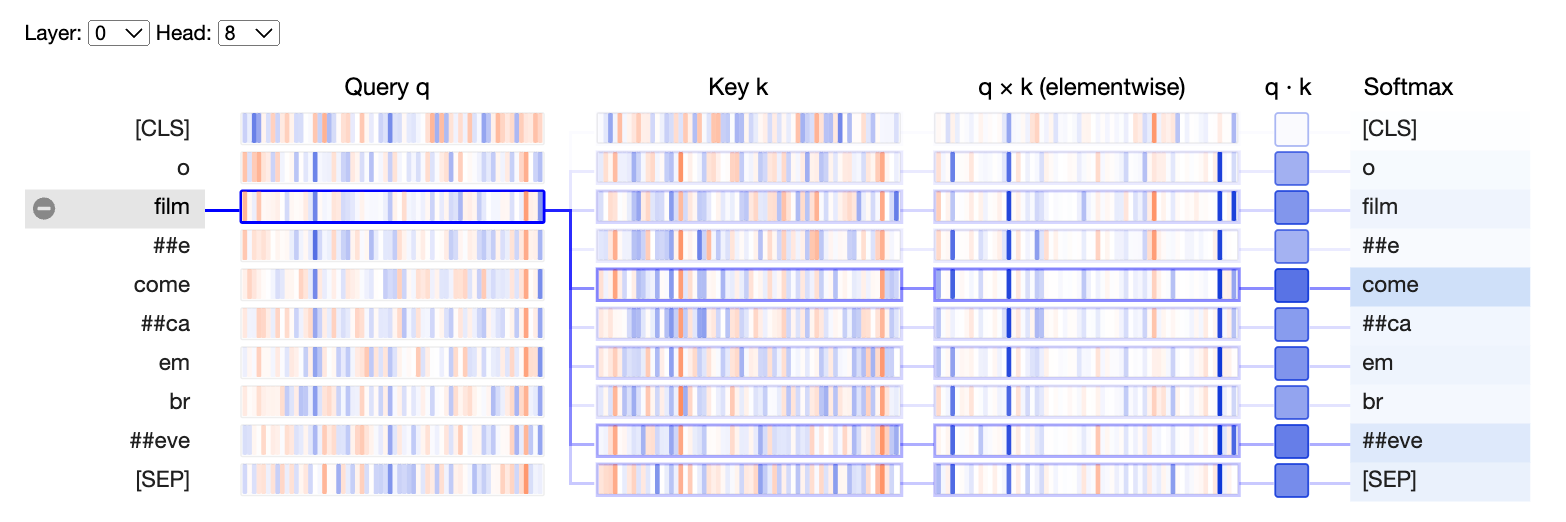
Para entender intuitivamente os conceitos de query (consulta), key (chave) e value (valor) no contexto dos mecanismos de atenção, imagine que você está em uma biblioteca, cheia de livros sobre uma variedade de tópicos. Seu objetivo é encontrar informações específicas sobre "astronomia". Nesse cenário:
- Query (Consulta): É como a pergunta que você tem em mente, ou o tópico específico que você está procurando, como "astronomia". Em termos de modelos de atenção, a query representa a informação que você deseja obter mais detalhes a partir dos dados.
- Key (Chave): São como as etiquetas ou os índices nos livros da biblioteca que ajudam você a identificar se um livro (ou parte dele) é relevante para sua consulta. As keys ajudam o sistema a determinar quão relevante ou importante cada pedaço de informação (ou livro) é em relação à query.
- Value (Valor): Se as keys ajudam você a encontrar os livros relevantes, os values são o conteúdo real desses livros. Depois de identificar quais livros são relevantes para sua consulta sobre "astronomia", você lê (ou extrai valor) desses livros. No contexto dos mecanismos de atenção, os values são os dados reais que você quer ponderar ou destacar com base na relevância identificada pelas keys em relação às queries.
Embora possa parecer confuso esses termos, nós já vimos esse processo antes.
- Calculando Scores de Atenção: Primeiro, medimos a compatibilidade entre cada query e todas as keys para determinar a relevância. Isso é feito calculando o produto escalar (um tipo de multiplicação) entre as queries e as keys. Depois, dividimos o resultado pela raiz quadrada da dimensão das keys (
sqrt(dim_k)), o que ajuda a normalizar os scores e torna o treinamento do modelo mais estável. - Determinando os Pesos de Atenção: Usamos a função softmax para converter os scores de atenção em pesos que somam 1. Isso significa transformar os scores brutos em probabilidades, indicando quão relevante cada parte dos dados (value) é em relação à consulta.
- Gerando os Outputs da Atenção: Finalmente, multiplicamos os pesos de atenção pelos values para obter o output final. Esse passo é como ler e agregar o conteúdo mais relevante dos livros selecionados. O resultado é um conjunto ponderado de informações que destaca os dados mais relevantes em resposta à consulta original.
Conclusão
Espero que esse artigo tenha te ajudado a entender um pouco mais sobre como funciona o mecanismo de atenção de um transformer. Nos vemos na próxima!



