Construindo um Portfólio que Realmente Importa
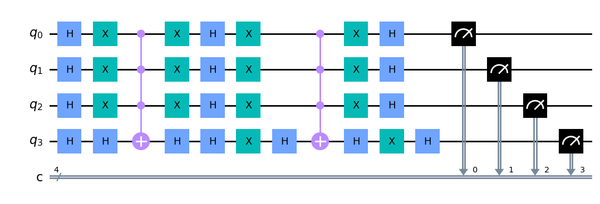
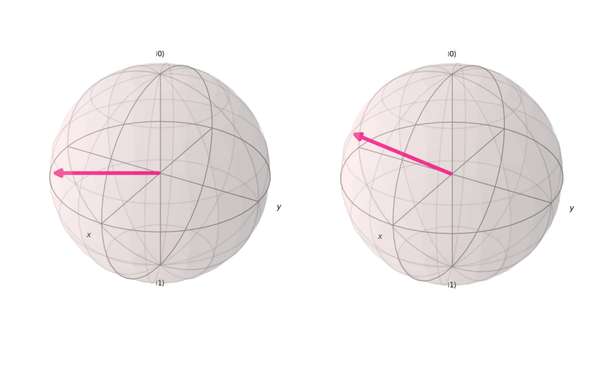
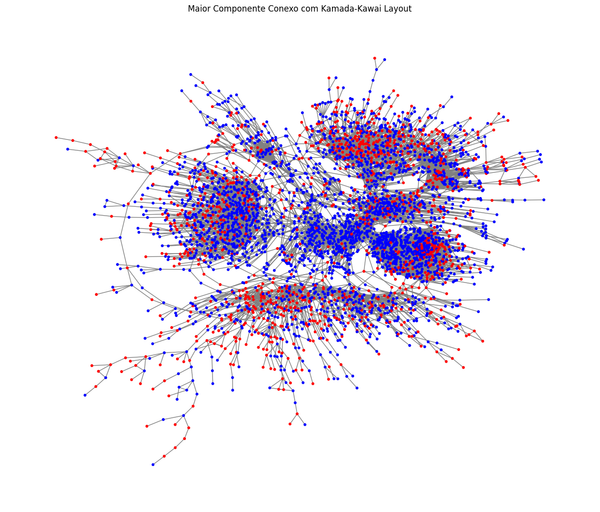
Portfólio em ciência de dados não é coleção de notebooks ou algoritmos empilhados. É mostrar como você pensa: formular perguntas, testar hipóteses e transformar dados em argumentos claros. O diferencial está na narrativa e na maturidade analítica, não na repetição de cases.