Transformers: Multi Head Attention para Análise de Sentimentos
Os Transformers transformaram a IA com o poder do multi-head attention, capaz de capturar múltiplas relações linguísticas em paralelo. Neste estudo de caso, implemento a arquitetura do zero e aplico em análise de sentimentos em português.


Introdução
Entender uma frase vai muito além de olhar palavra por palavra. Precisamos relacionar conceitos, ignorar ambiguidades óbvias e destacar o que realmente importa. Nos Transformers, essa tarefa é dividida entre várias “cabeças” de atenção, cada uma olhando para o texto de um ângulo distinto.
Os Transformers se tornaram a espinha dorsal de praticamente todos os avanços significativos em processamento de linguagem natural dos últimos anos. BERT revolucionou a compreensão de texto, GPT redefiniu a geração de linguagem, e Vision Transformers provaram que essa arquitetura transcende modalidades. O denominador comum entre todos eles é o mecanismo de Multi-Head Attention.
O conceito central é simples: em vez de processar sequências palavra por palavra como fazem as RNNs, os Transformers permitem que cada posição "preste atenção" simultaneamente a todas as outras posições da sequência. Mas a verdadeira potência está no "multi-head" - a capacidade de ter múltiplas representações de atenção operando em paralelo, cada uma capturando aspectos diferentes das relações entre palavras.
Por que precisamos de múltiplas cabeças de atenção? Uma única função de atenção é limitada em sua capacidade representacional. Uma cabeça pode capturar relações sintáticas, enquanto outra foca em dependências semânticas. Uma terceira pode identificar padrões de sentimento, e uma quarta pode mapear referências pronominais.
Parti de uma SimpleAttention apresentada em meu artigo anterior. Em seguida, expandi para MultiHeadAttention, onde múltiplas representações paralelas capturam diferentes aspectos do texto.
Quando observamos como diferentes cabeças processam a mesma sentença, vemos padrões distintos emergindo. Uma cabeça pode conectar fortemente sujeitos a seus verbos, enquanto outra mapeia adjetivos a substantivos. Essa especialização implícita, que emerge durante o treinamento sem supervisão explícita, é o que confere aos Transformers sua capacidade de modelar linguagem.
A Base: O Mecanismo de Atenção Simples
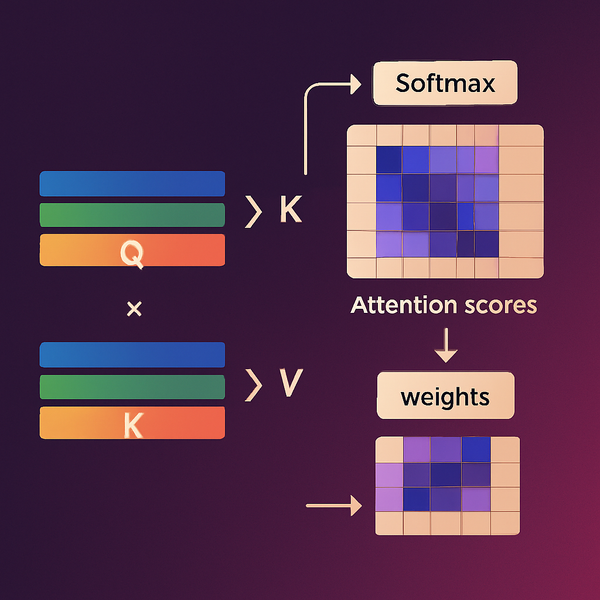
Como um token em uma sequência pode "saber" quais outros tokens são relevantes para seu contexto? A resposta está na elegante simplicidade das três transformações lineares que definem a atenção: Query, Key e Value.
O mecanismo de atenção é, fundamentalmente, uma função que mapeia queries e um conjunto de pares key-value para uma saída. Cada token na sequência gera simultaneamente uma query (o que ele está "procurando"), uma key (como ele pode ser "encontrado") e um value (o que ele contribui quando é "encontrado"). Esta tripla transformação é o que permite aos Transformers capturar dependências de longo alcance sem a limitação sequencial das RNNs.
class SimpleAttention(nn.Module):
def __init__(self, model_dim, head_dim, attn_dropout=0.0):
super().__init__()
self.W_q = nn.Linear(model_dim, head_dim, bias=False)
self.W_k = nn.Linear(model_dim, head_dim, bias=False)
self.W_v = nn.Linear(model_dim, head_dim, bias=False)
self.head_dim = head_dim
self.dropout = nn.Dropout(attn_dropout)
def forward(self, x, attention_mask=None):
Q, K, V = self.W_q(x), self.W_k(x), self.W_v(x)
scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.head_dim)
if attention_mask is not None:
m = attention_mask[:, None, :]
scores = scores.masked_fill(~m, float('-inf'))
A = F.softmax(scores, dim=-1)
A = self.dropout(A)
out = A @ V
return out, AImplementei o masking opcional através de scores.masked_fill(~m, float('-inf')) porque muitas aplicações requerem controle sobre quais tokens podem "ver" quais outros. Em modelos causais, por exemplo, tokens futuros devem ser mascarados para preservar a propriedade autoregressiva.
Os pesos das matrizes W_q, W_k e W_v não são programados - eles são aprendidos através de backpropagation.
Multi-Head Attention: Múltiplas Perspectivas Simultâneas
A atenção simples tem uma limitação fundamental: ela processa toda a informação através de uma única lente de interpretação. Quando expandimos essa arquitetura para múltiplas cabeças de atenção paralelas, criamos algo mais poderoso — um sistema que pode simultaneamente capturar diferentes tipos de relacionamentos na mesma sequência de entrada.
A classe MultiHeadAttention implementa essa expansão criando múltiplas instâncias de atenção simples que operam em paralelo. Cada cabeça recebe a mesma entrada mas desenvolve sua própria especialização durante o treinamento. O mecanismo é direto: dividimos a dimensão oculta pelo número de cabeças, garantindo que cada uma opere em um subespaço menor mas complementar.
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
H, D = config.num_attention_heads, config.hidden_size
assert D % H == 0, "hidden_size deve ser múltiplo de num_heads"
d_k = D // H
self.num_heads = H
self.heads = nn.ModuleList([
SimpleAttention(D, d_k, attn_dropout=config.hidden_dropout_prob)
for _ in range(H)
])
self.out_proj = nn.Linear(D, D)
self.resid_dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, attention_mask=None, head_mask=None):
outs, attns = [], []
if head_mask is None:
head_mask = hidden_states.new_ones(self.num_heads)
for i, head in enumerate(self.heads):
o, A = head(hidden_states, attention_mask=attention_mask)
o = o * head_mask[i].view(1,1,1)
outs.append(o)
attns.append(A.unsqueeze(1))
x = torch.cat(outs, dim=-1)
x = self.resid_dropout(self.out_proj(x))
attn = torch.cat(attns, dim=1)
return x, attnA visualização dos quatro heads processando a frase "Este filme é absolutamente incrível" revela como cada cabeça desenvolve especializações distintas. O Head Sintático concentra sua atenção em tokens adjacentes, criando conexões gramaticais locais. O Head Semântico estabelece pontes entre palavras semanticamente relacionadas — observe como conecta "filme" e "incrível" mesmo estando distantes na sequência.
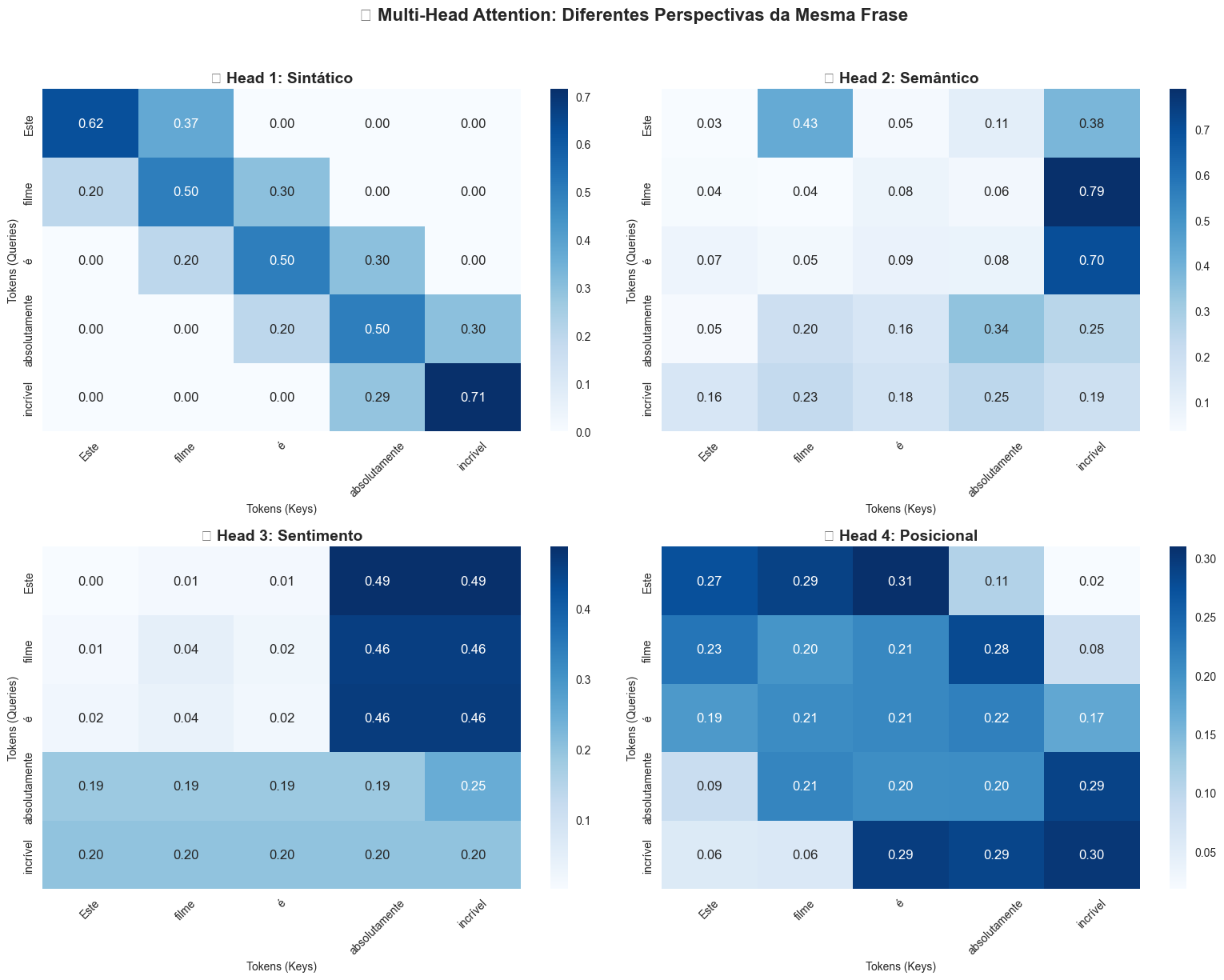
O Head de Sentimento demonstra comportamento particularmente interessante ao amplificar conexões com palavras emotivas como "absolutamente" e "incrível", criando um mapa de intensidade emocional da frase. O Head Posicional desenvolve padrões baseados na estrutura sequencial, mantendo uma noção de ordem e proximidade relativa.
Essa especialização automática é o que torna o multi-head attention tão poderoso. Durante o treinamento, cada cabeça encontra sua própria forma de contribuir para a tarefa final, sem supervisão explícita sobre que tipo de relacionamento deve capturar. O resultado é uma decomposição natural da complexidade linguística em aspectos complementares.
Após cada cabeça processar independentemente a entrada, concatenamos suas saídas e aplicamos uma projeção linear final. Essa etapa permite que o modelo combine as diferentes perspectivas em uma representação unificada.
Como as cabeças operam independentemente, podem ser processadas em paralelo, aproveitando melhor o hardware. Isso contrasta com abordagens sequenciais que processariam cada perspectiva uma de cada vez.
Arquitetura Completa: Feed-Forward e Conexões Residuais
O segundo componente fundamental de cada camada do Transformer é a rede feed-forward. Enquanto a atenção captura relacionamentos entre diferentes posições na sequência, a rede feed-forward processa cada representação individualmente, aplicando transformações não-lineares que permitem ao modelo "pensar" sobre cada token separadamente.
Na classe FeedForward, a rede expande temporariamente as dimensões de hidden_size para intermediate_size — tipicamente um fator de 4x. Aplica uma função de ativação não-linear, e então comprime de volta às dimensões originais. Essa expansão dimensional cria um espaço computacional maior onde interações complexas podem ser capturadas antes da compressão final.
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.resid_dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.dropout(x)
x = self.linear_2(x)
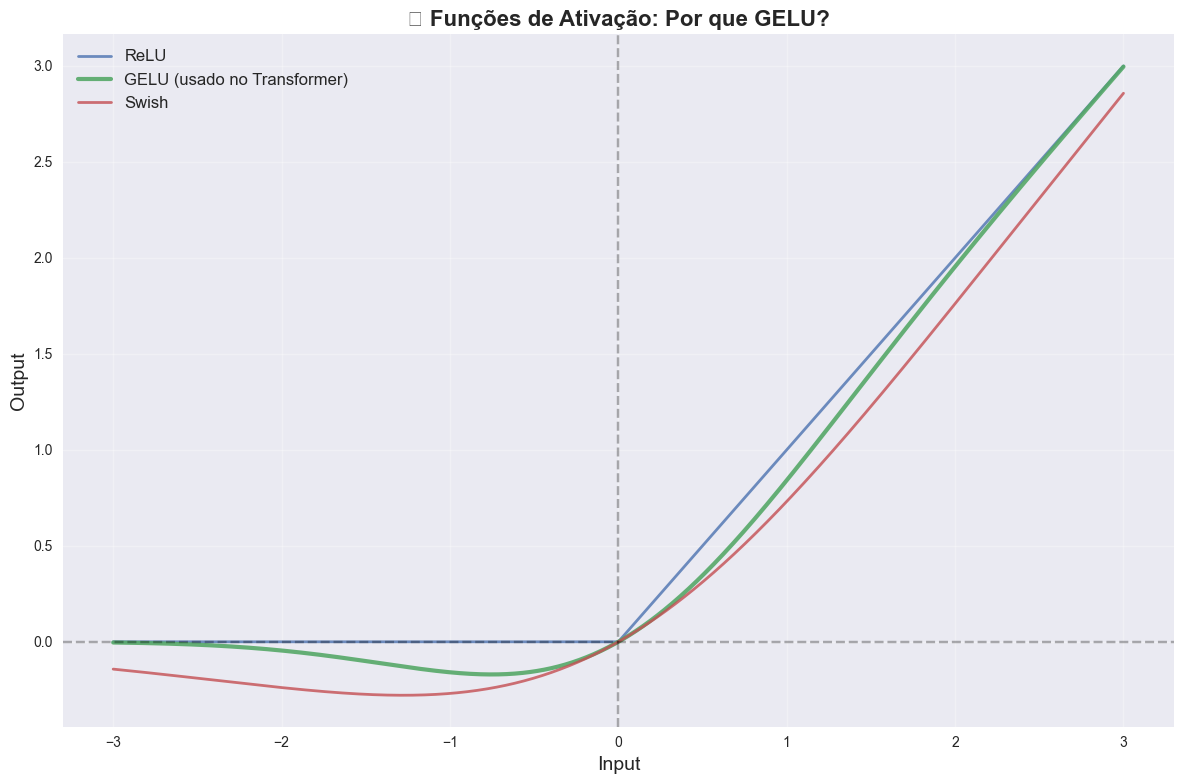
return self.resid_dropout(x)A função GELU se tornou padrão em Transformers. Diferente da ReLU, que zera abruptamente valores negativos, a GELU oferece uma transição suave que preserva gradientes mesmo para valores ligeiramente negativos. Essa suavidade ajuda que o treinamento seja estável, onde gradientes pequenos mas não-zero podem carregar informação importante.
A integração desses componentes na classe TransformerEncoderLayer implementa a arquitetura Pre-Layer Normalization, onde a normalização acontece antes das operações principais, não depois. Essa arquitetura facilita o treinamento de modelos profundos ao estabilizar o fluxo de gradientes.
class TransformerEncoderLayer(nn.Module):
def forward(self, x, attention_mask=None, head_mask=None):
hidden_states = self.layer_norm_1(x)
y, attn = self.attention(hidden_states, attention_mask=attention_mask, head_mask=head_mask)
x = x + y
y = self.feed_forward(self.layer_norm_2(x))
x = x + y
return x, attnA arquitetura aqui pode ser empilhada para formar modelos mais profundos. Cada camada adicional aumenta a capacidade do modelo de capturar padrões mais abstratos e relacionamentos de longo alcance, mantendo a estabilidade de treinamento através das conexões residuais e normalização.
Embeddings: Convertendo Texto em Representações Numéricas
O sistema de embeddings é essa ponte entre linguagem humana e processamento matemático. Modelos neurais operam exclusivamente com tensores numéricos, mas a linguagem natural é sequencial e simbólica. Precisamos de uma representação que capture não apenas o que cada palavra significa, mas onde ela aparece na sequência.
Implementei um sistema bastante simples que combina dois tipos de embeddings: token embeddings que capturam significado semântico, e position embeddings que preservam informação posicional. A classe Embeddings demonstra essa arquitetura:
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.embedding = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embedding = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids):
seq_len = input_ids.size(1)
position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0).expand_as(input_ids)
embeddings = self.embedding(input_ids) + self.position_embedding(position_ids)
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddingsO mecanismo é bem direto. Para cada token na sequência, faço lookup em duas tabelas de embedding simultaneamente: uma indexada pelo ID do token, outra pela posição absoluta. A soma dessas representações cria vetores que codificam tanto identidade lexical quanto localização sequencial.
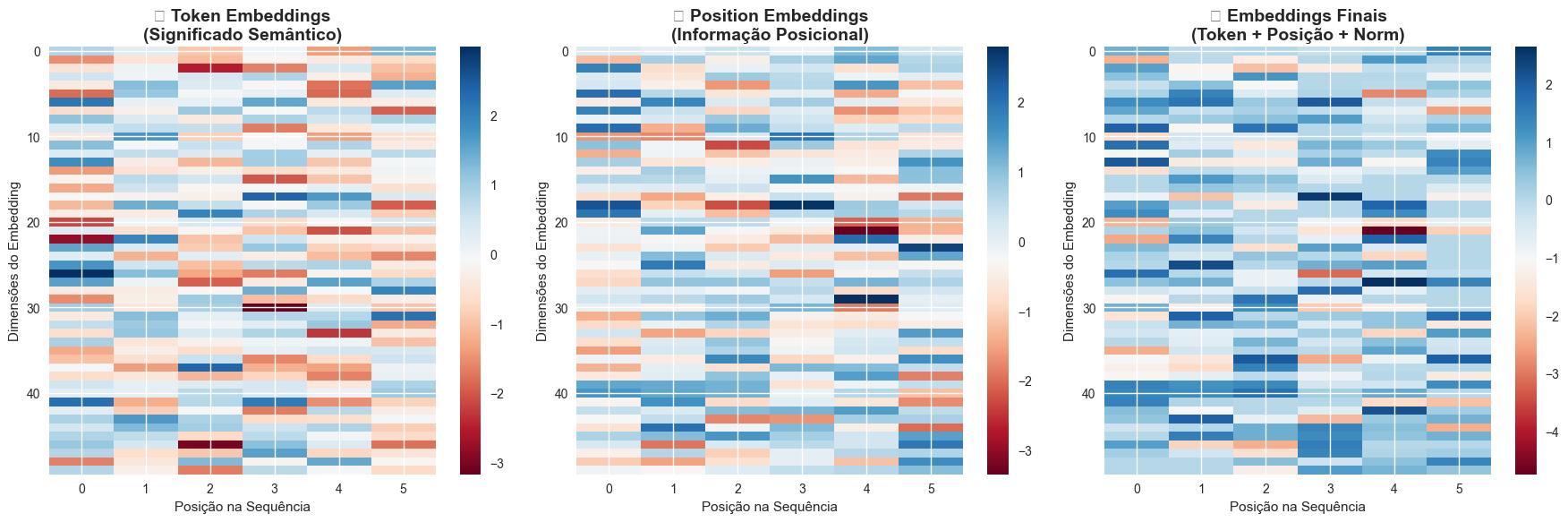
O mesmo token em posições diferentes produz vetores distintos, permitindo que o modelo distinga "João ama Maria" de "Maria ama João". A posição é tão importante quanto conteúdo. Sem embeddings posicionais, o Transformer seria invariante à ordem das palavras.
Colocando o Transformer em Ação
Depois de construir todas as peças do Transformer, chegou o momento de integrá-las em um sistema completo de classificação.
class TransformerForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__()
self.encoder = TransformerEncoder(config)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, attention_mask=None):
h = self.encoder(input_ids, attention_mask=attention_mask)
if attention_mask is None:
pooled = h.mean(dim=1)
else:
m = attention_mask.unsqueeze(-1).type_as(h)
pooled = (h * m).sum(dim=1) / m.sum(dim=1).clamp_min(1e-6)
x = self.dropout(pooled)
return self.classifier(x)Quando temos sequências de comprimentos diferentes, uma simples média aritmética incluiria posições de padding, distorcendo as representações finais. A implementação usa média ponderada baseada na attention mask, garantindo que apenas tokens válidos contribuam para a representação final da sequência.
Construí um tokenizador personalizado que utiliza expressões regulares para segmentar texto em palavras, números e pontuação. Com apenas 1.762 tokens únicos, consegui cobrir 90.23% do dataset.
def build_vocab(texts, max_size=30000, min_freq=2):
cnt = Counter()
for t in texts:
cnt.update(SimpleTokenizer.basic_tokenize(t))
most = [w for w,c in cnt.most_common(max_size) if c >= min_freq]
vocab = [PAD, UNK] + most
return vocabTreinei esse Transformer ao longo de apenas 50 épocas. A loss diminuiu consistentemente de 1.102 para 0.613, o que indicou algum aprendizado. Os resultados no conjunto de teste mostraram performance moderada mas significativa: 54.3% de acurácia, que supera substancialmente o acaso (33.3% para três classes). O AUC foi 0.730, o que demonstra que o modelo possui boa capacidade discriminatória - consegue distinguir efetivamente entre sentimentos diferentes, mesmo quando não acerta a classe exata.
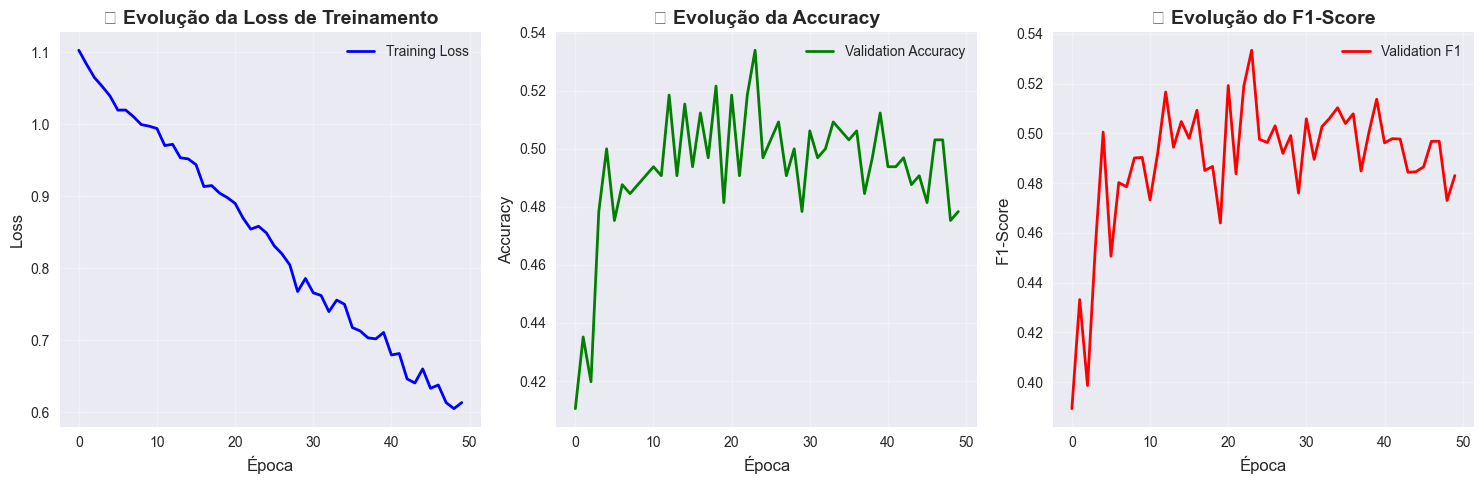
O modelo, por mais simples que seja, aprendeu representações semânticas úteis, capturando nuances linguísticas que permitem discriminação entre sentimentos.
Conclusão
Implementar um Transformer do zero me mostrou que a “elegância” dessa arquitetura não vem de componentes complexos, mas da combinação de blocos relativamente simples. Atenção, feed-forward, embeddings e conexões residuais são peças bastante diretas. É a soma de componentes simples, mas em uma estrutura elegante, que explica por que os Transformers se tornaram a base dos modelos modernos.
Ainda não sei qual será meu próximo passo. Quero explorar variantes mais sofisticadas, mas também quero aplicar esse mesmo esqueleto a outros domínios. Se você curtiu esse artigo, assine a newsletter para acompanhar os próximos.