PSI - monitoramento e feature selection

Imagine que estamos no mês de janeiro e você quer ajudar o time de marketing a melhorar os anúncios realizados e direcionar campanhas personalizadas para os clientes com maior probabilidade de converterem.
Para fazer isso você utiliza os dados históricos dos últimos 3 meses (outubro, novembro e dezembro) de todos os clientes para treinar um modelo de machine learning capaz de prever a probabilidade de conversão. Analisando as features mais importantes, você percebe que seu modelo está analisando os hábitos de consumo dos clientes para determinar a probabilidade de conversão.
Dentre esses hábitos de consumo estão informações como o volume gasto em compras online, a porcentagem da renda que foi gasta com compras, o volume financeiro gasto em cartões de crédito, etc.
As informações analisadas pelo seu modelo parecem fazer sentido e as métricas de performance mostram que seu modelo está funcionando bem. Seu modelo entra em produção e durante os próximos 2 meses é utilizado para determinar a probabilidade de conversão dos clientes.
Só que as coisas não saíram como esperado...
Entretanto, 2 meses após seu modelo entrar em produção (março) você começa a observar que os resultados obtidos em produção estão totalmente diferentes dos resultados que você esperava obter quando criou o modelo. O que pode ter acontecido?
Esse é um caso clássico. Lembre-se que os hábitos de consumo da população brasileira nos 3 últimos meses do ano (outubro, novembro e dezembro) são totalmente diferentes dos hábitos nos demais meses do ano, seja por conta das festividades de fim de ano, recebimento do décimo terceiro, promoções de black friday, etc. Seu modelo aprendeu um comportamento que não se repetiu durante os meses seguintes. Pior que isso, seu modelo não aprendeu o comportamento "normal" que ocorre fora desses meses. Ou seja, seu modelo aprendeu com base em um cenário, mas precisou atuar em outro cenário completamente diferente.
Uma possível solução é utilizar o PSI
É aí que entra o PSI (Population Stability Index). PSI é uma métrica que mede as mudanças em uma distribuição de variável. Ou seja, ela mede o quanto uma variável muda ao longo do tempo. Por isso, essa métrica é comumente utilizada para avaliar o risco de usar uma variável em um modelo preditivo.
Isso acontece porque variáveis que mudam muito ao longo do tempo representam um risco de instabilidade no modelo. Em cenários críticos, como modelagem de risco de crédito por exemplo, essa instabilidade pode ter um custo muito alto e não pode acontecer.
Dessa forma, o PSI é muito utilizado na seleção de features para eliminar aquelas que mudam muito e representam um risco para o modelo. A formula para calcular o PSI é:
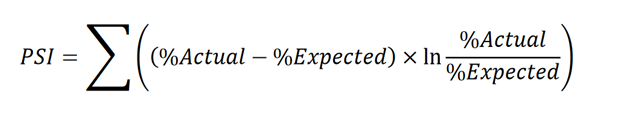
Em que Actual é a fração de observações nos dados de teste e Expected é a fração de observações nos dados de referência. Os dados de referência podem ser aqueles coletados em produção (no caso de monitoramento) ou até dados históricos (no caso de seleção de features).
Se a distribuição da variável não apresentar diferenças nos dois cenários, então as frações Expected e Actual serão muito semelhantes, e assim o valor do PSI será próximo de zero. Valores maiores do PSI indicam que a variável sofreu uma modificação grande entre os dois cenários e, por isso, representa um risco maior.
Concluindo...
O PSI é muito utilizado para selecionar as features mais estáveis para um modelo preditivo e reduzir o risco causado por informações instáveis ao longo do tempo. Depois, o PSI é utilizado para monitorar a população, identificar mudanças não previstas anteriormente e emitir o alerta de que algo precisa ser feito.



