Modelo preditivo prejudicado por erros humanos: identificando e corrigindo anomalias em dados da COVID-19

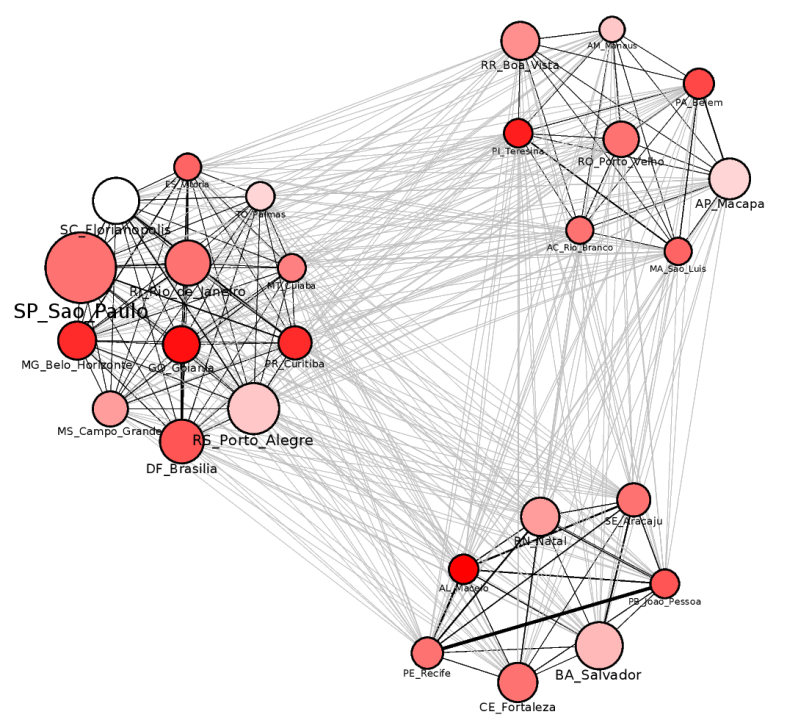
E se a performance do modelo preditivo for afetada por erros humanos cometidos na coleta dos dados? Estive envolvido em um trabalho que buscava prever o número diário de casos da COVID-19 nas capitais do Brasil considerando algumas métricas correlacionadas, como dados de clima e mobilidade urbana. Infelizmente, o modelo cometia alguns erros significativos ao prever a quantidade de casos. O desafio era identificar se o problema estava no modelo ou no conjunto de dados.
Eu apliquei uma técnica de detecção de anomalias que desenvolvi para analisar a variação diária no número de casos em comparação com as capitais mais próximas. Essa análise dos dados com a estrutura relacional da rede revela locais cuja variação na quantidade de casos é potencialmente anômala. Eu comparei o conjunto de anomalias identificado pela técnica com os erros do modelo preditivo. O resultado apontou que mais de 90% das anomalias estava diretamente relacionada com os erros que o modelo cometeu. Existia um forte indício de que os erros cometidos pelo modelo eram ocasionados por anomalias existentes no conjunto de dados. A Figura abaixo evidencia a relação entre erros do modelo com as anomalias, basta observar como as duas curvas (anomalia x erros) são bem similares.

Descobri que, na maioria dos casos, erros humanos no processo de coleta dos dados foram responsáveis pelas anomalias que afetaram a performance do modelo. Por exemplo, existiam dias em que a quantidade de casos era negativa (para compensar um registro errado feito em dias anteriores). Além disso, em alguns feriados e finais de semana os dados não eram registrados em algumas regiões. Quando isso acontecia, o acumulado desses dias era registrado no próximo dia útil, gerando um pico no número de casos que não condizia com a realidade.
Apliquei uma outra técnica voltada para normalização dos dados para tentar corrigir essas anomalias. Essa técnica utiliza a estrutura relacional dos dados para normalizar os valores nos nós dessa rede. A Figura abaixo ilustra o que acontece com os dados observados e os dados normalizados. É possível observar que os picos, em sua maioria anômalos, são amortizados pela técnica que considera as regiões próximas.

Executamos o modelo novamente com a base de dados normalizada e obtivemos uma redução de 30% no erro médio do modelo preditivo. Esse resultado mostra que erros sutis no conjunto podem afetar significativamente a performance de modelos preditivos e evidencia a necessidade de analisar o conjunto de dados buscando por anomalias que vão além das clássicas. Vou deixar aqui o link do artigo com esse estudo.



